数据库集群(Database Cluster)深度解析与概念解析

数据库cluster指的是数据库集群,是一种将多台数据库服务器组合在一起,共同协作以提供更高性能、可靠性和可扩展性的技术,通过将数据分散存储在多个服务器上,并协同处理查询请求,数据库集群能够实现负载均衡、故障转移和数据的冗余备份等功能,这种技术广泛应用于大型企业级应用,以确保数据库的高性能、高可靠性和高可扩展性。

如何设置聚集索引(Cluster Index):
使用SQLServerManagementStudio:
- 在“对象资源管理器”中,展开要创建聚集索引的表。
- 右键单击“索引”文件夹,指向“新建索引”,然后选择“聚集索引…”。
- 在“新建索引”对话框的“常规”页中,输入新索引的名称。
- 在“索引键列”下,单击“添加…”,选择要添加到聚集索引的表列。
- 使用表设计器创建聚集索引。
使用Transact-SQL:
在“对象资源管理器”中连接到数据库引擎的实例,在标准菜单栏上单击“新建查询”,然后将相关示例代码粘贴并单击“执行”。
RAC的含义:
RAC=RealApplicationCluster,是ORACLE数据库自己的集群系统,装RAC的数据库需要先装clusterware,配置好集群后,从集群的任一节点装数据库,就可以通过rac的集群软件同步到集群的其他节点了,RAC是同时提供服务,而双机热备是只有一个提供服务,另外一个通过同步机制保持数据同步。
大数据与Hadoop之间的关系:
大数据是一系列技术的统称,经过多年的发展,已经形成了从数据采集、整理、传输、存储、安全、分析、呈现和应用等一系列环节,Hadoop是目前比较常见的大数据支撑性平台,提供了分布式存储、分布式计算、任务调度、对象存储和组件支撑服务等功能,随着Hadoop的不断发展,基于Hadoop的大数据生态越发完善,包括诸多组件的开发和应用极大地丰富了Hadoop自身的功能和应用场景,随着组件的增多,Hadoop自身也越来越重,因此很多大数据工程师更愿意使用Spark等更轻更快的工具,由于Hadoop对硬件的要求并不高,所以很多初学者都是从Hadoop开始学习大数据的,随着商用大数据平台的普及,Hadoop的地位愈发重要。
Java包括的内容:
经过20多年的发展,Java从最初的嵌入在网页中的Applet发展到几乎各个开发领域,Java技术提纲包括JavaSE(标准版)、JavaFX(图形用户界面解决方案)、JavaSE中的诸多细节(网络编程、平台适配等)、JavaEE(企业级Java解决方案)、JavaME(嵌入式设备开发)、JavaCard(智能卡应用)、JavaTV(数字化TV应用)和JavaDB(数据库应用)等,还有基于Java的开源分布式图数据库HC4和Oracle的数据表存储结构中的索引组织表(IOT)等。
HC4的含义:
HC4是HyperGraphDBCloudComputingCluster的简写,它是一个基于Java的开源分布式图数据库,它提供了基于RESTful服务的WebAPI,让开发人员在任何平台上都能使用图形数据库,HC4的主要特性包括共享内存集群、多核支持、高性能等,目的是提供一个可靠、可扩展的图形数据库,以满足企业和个人的需求。
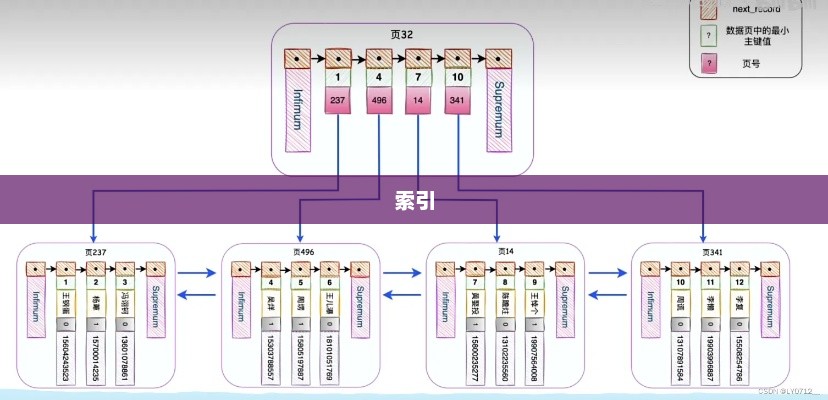
SQL中的iot:
在Oracle数据库中,iot是索引组织表(Index Organization Table)的缩写,区别于堆表,IOT的数据行组织不是随机的,而是依据数据表主键,按照索引树进行保存,从段结构上看,IOT的索引段包含了所有数据行列,不存在单独的数据表段。