
华为昇腾集群训练性能超越DeepSeek-R1,自研模型展现无英伟达实力

摘要:
华为昇腾集群训练性能强大,堪比DeepSeek-R1,且完全自主研发,不含英伟达成分,其自研模型展现出强大的实力,在人工智能领域取得了重要进展,这一成就彰显了华为在自主研发和技术创新方面的实力与决心。
华为昇腾集群训练性能强大,堪比DeepSeek-R1,且完全自主研发,不含英伟达成分,其自研模型展现出强大的实力,在人工智能领域取得了重要进展,这一成就彰显了华为在自主研发和技术创新方面的实力与决心。
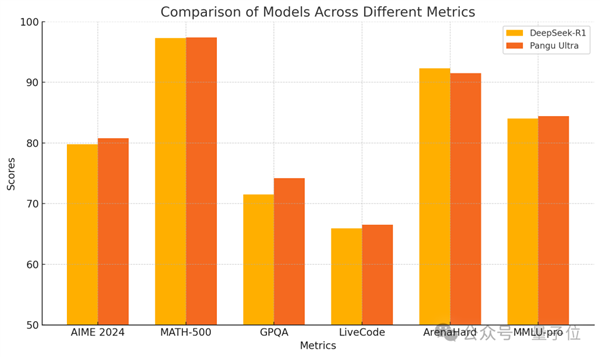
华为推出的盘古Ultra模型展现了其在人工智能领域的显著进展,该模型采用纯昇腾集群进行训练,性能与英伟达的DeepSeek-R1相当,且不含英伟达成分。 盘古Ultra模型在密集模型推理能力方面与DeepSeek-R1展开竞争,在数学竞赛和编程等推理任务中,盘古Ultra模型展现了卓越性能,其参数量仅有135B,且训练过程中未使用任何英伟达的硬件或技术,损失函数的波动得到有效控制。 盘古Ultra模型通过创新的模型架构和系统优化策略,展现出超过52%的算力利用率,网友们特别关注训练过程中没有出现损失尖峰这一特点,这在之前是难以实现的,该模型通过深度缩放的Sandwich-Norm层归一化和TinyInit参数初始化策略,解决了训练超深网络的不稳定性和收敛困难问题,针对Tokenizer的优化以及大规模计算集群的使用,进一步提升了模型的性能。 盘古Ultra的出现标志着我国在人工智能领域的重要进展,该模型的纯昇腾集群训练和卓越性能为我们展示了人工智能的无限潜力,对于更多技术细节,可以通过访问指定链接查看技术报告,该模型的成功也反映了我国在科技领域的持续进步和创新能力。




